An Attempt to Explain Relational and Document Storage
The goal of data storage on the internet is to be able to quickly, accurately, and safely retrieve that information.
In the case of a web application, the questions might be as simple as "What is this user's name?" or as complex as "Tell me the average amount of time a user spends on your website when they're making a purchase between $50 and $100".
The fundamental unit of representation within a database is a key:value pair. A key is the naming structure for some unit of information and the value is the unit that that information represents.
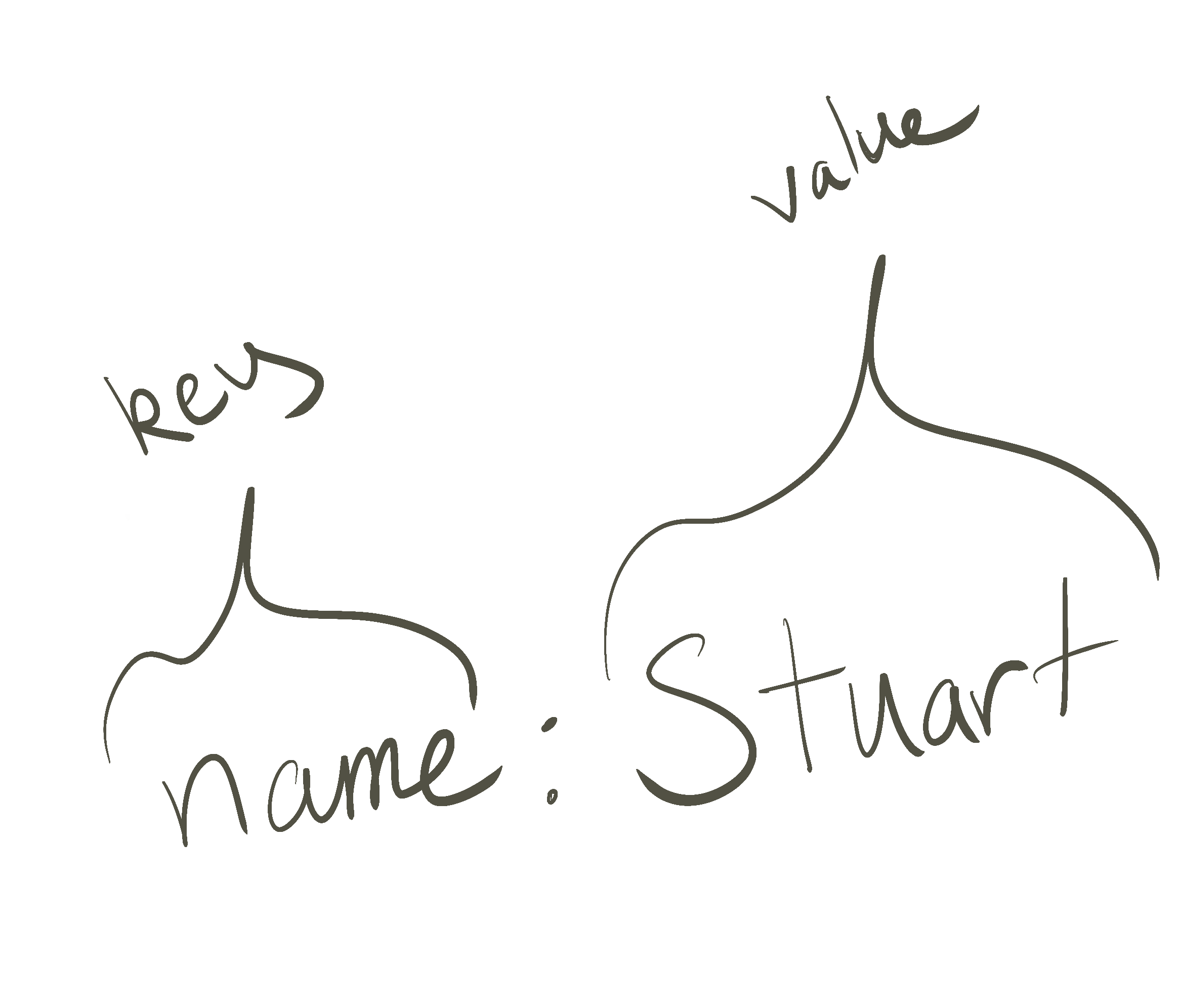
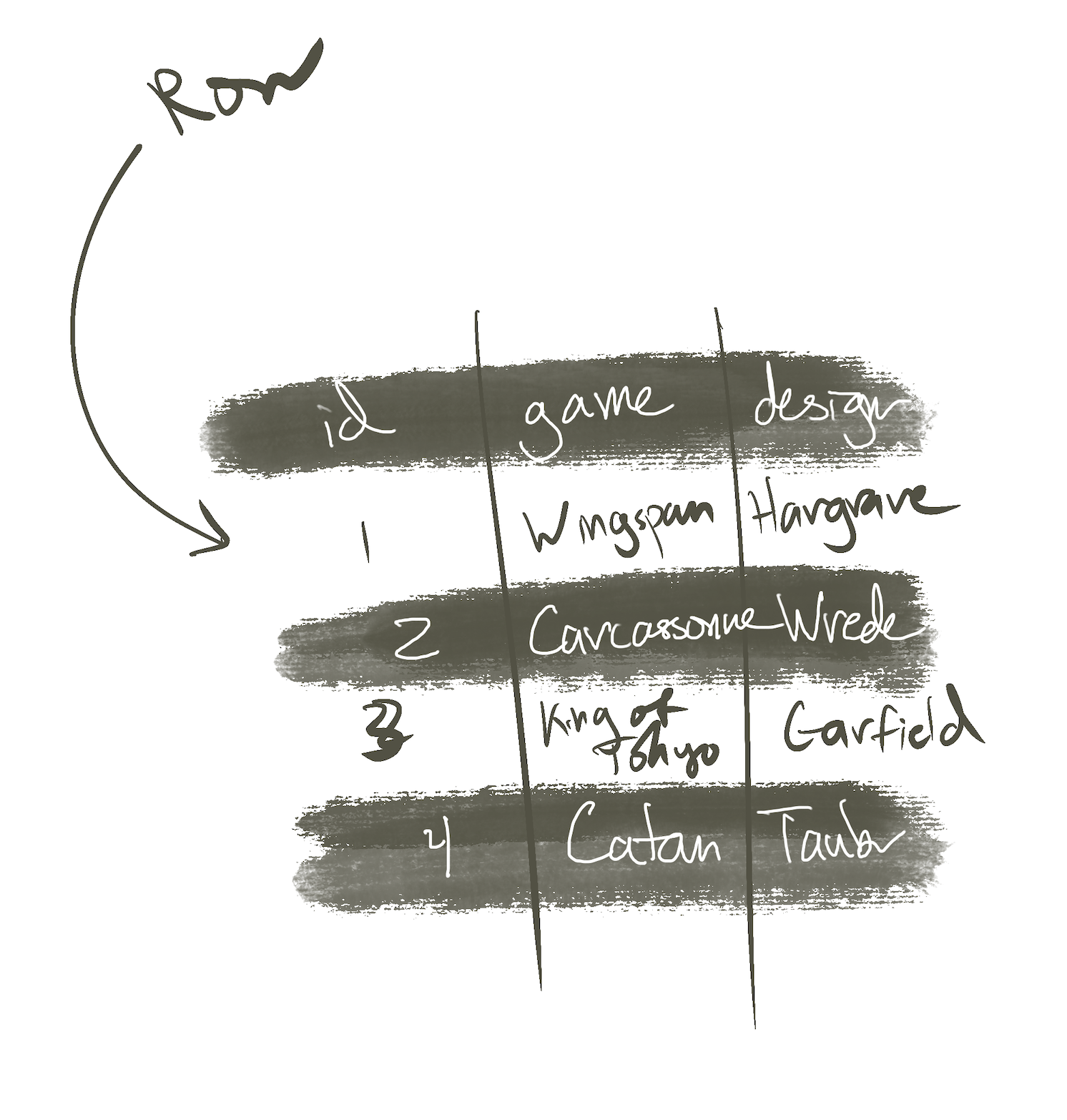
And the key value pairs are grouped into sets of data called rows. You can roughly think of these like Excel spreadsheets. There are many different types of databases that are suited to different types of purposes, but fundamentally they're all groupings of rows with key value pairings of information.
Relational Databases
For a very long time relational storage has been the predominant way we think about and store data within a database. It's so named because the value of the database is in the relationships between information being stored. Relational databases rely on "Tables" which are unique groupings of rows. You can basically think of these like different tabs in an excel spreadsheet. One of the core facets of relational databases is that you shouldn't duplicate data, instead referencing the relationship via a "foreign key". A foreign key is basically the number and the value pointing to the id of another relationship.
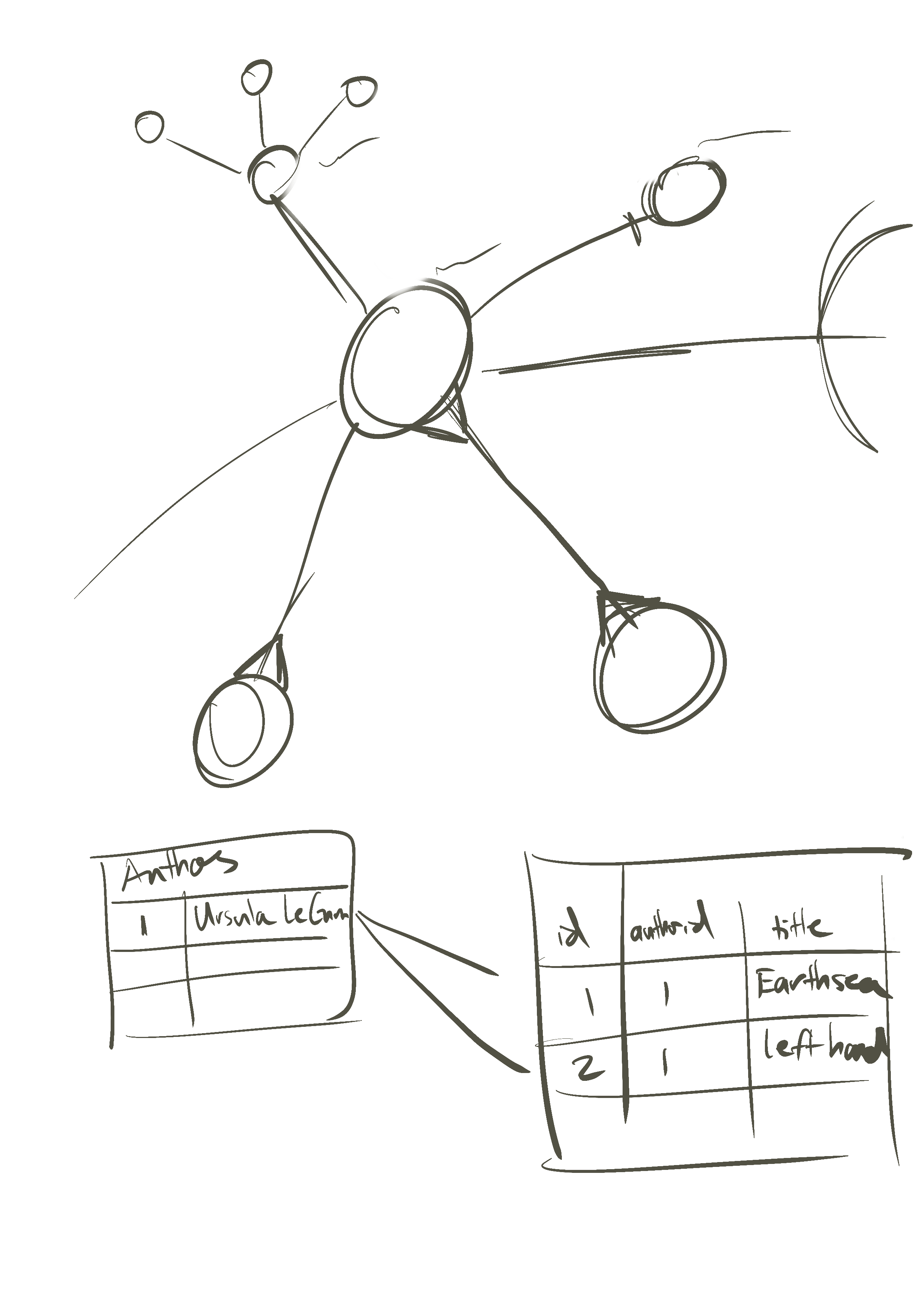
The benefit to relational database is that it's always internally consistent. It's impossible to set a value of a relationship that doesn't exist, and it's impossible to remove data in such a way that would make the relationship disappear. This is a powerful modeling technique and a good heuristic with which to think about the world. For example, if you wanted to create a simple model of an author with books, you could create two tables. An authors table with a list of authors, and a books table which links to those authors. This compounding set of relationships can help maintain internal consistency and ask relatively complex questions based on the relationships between unrelated tables, by following the linkage between relationships. I.e. If you were searching for a book, you would be able to access it by looking through genre, author, or edition. Any of these might point you to a reference that you could then use to find the book.
However, this consistency comes with a heavy cost. In order to maintain its internal consistency, before any data is added, updated, or removed the database has to check whether or not it is allowed to do such an operation. Which means if you are trying to do many many of these things at once, the system can grind to a halt.
Document Storage
Document storage to the rescue! If there's been one trend in the last 50 years of computing technology it's that the cost of storing stuff has only gotten cheaper and cheaper. Now it's cheap to buy a small flash drive that stores multiple terabytes of data. This paradigm shaft has had implications for how we think about data storage. Namely, that the whole "not duplicating data" paradigm is silly and impractical. The cost of storing data is trivial, so trivial in fact, that it's smarter to duplicate it rather than to make it internally consistent. Far better, document storage argues, is to focus on the actual expensive part, the act of creating, updating, or removing a record.
If you think about a relational database from a birds eye view seeing the connections between different sets of data, a document store is more like a profile view of a decision tree figuring out how to "access" that data.
Instead of organizing data in tables, or logically consistent forms of key value pairs, data is organized by indexes, or the way that information is typically accessed and retrieved. If we continue our library metaphor, instead of referencing a single book in multiple different ways, you would simply buy multiple copies of the book, and then put it in all of the locations one might expect to find it. If you had a genre section of your library, you would look in the appropriate genre and find a copy there. If you had an author section, you might find it there. There would be multiple books stored in multiple places based on how you expect to find the book.
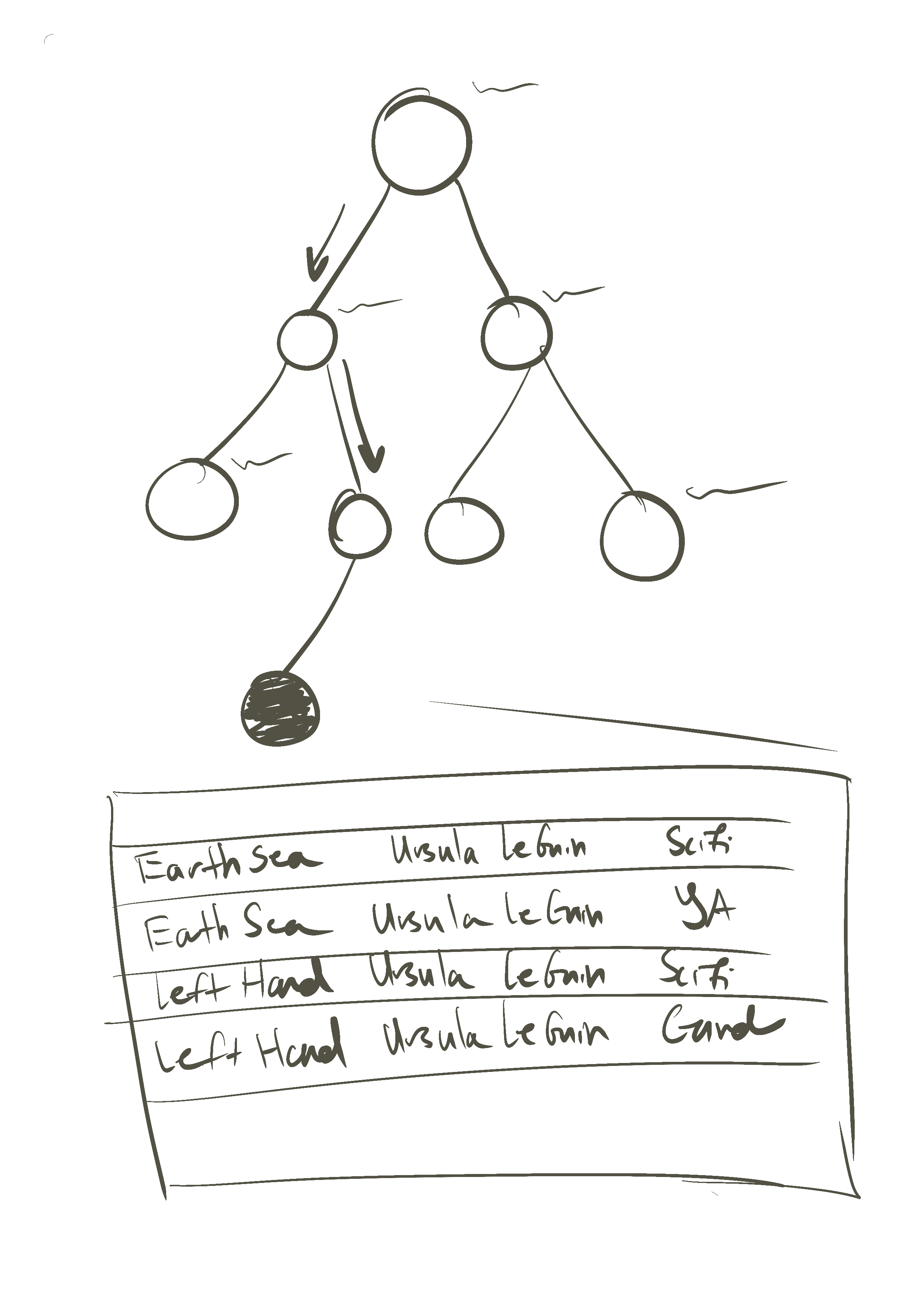
The downside to this, of course, is that now if something about the book changes you can't simply update one location and be good, you have to update every location. But, in our magical sorting library you could simply ask for all of the books of a single title, and update all of them at once.
The downside to this sort of behavior is that you can't guarantee that at any given time, the information stored will be 100% up to date, because the database isn't making any effort to do so. You can only guarantee that it will be eventually up to date. One of the biggest challenges of this method of data storage is twofold. One, it's a completely different way to think about the world. Even if it's complicated to map out the relationship between books and authors and genres (there are PhDs dedicated to the library sciences), it's a somewhat intuitive way of thinking about the stuff we might want to represent in code. But thinking about data in terms of how you fetch it is foreign, both because it's not how we're taught, but also because it's challenging to visualize the act of accessing data.
Pros and Cons
At the start I talked about the fundamentals of data storage being able to quickly, accurately, and safely retrieve the appropriate information at the right time. And a developer's choice of which location they want to throw their data will depend on what each of those means to them. For example, if accuracy means "I must be able to freeze time at any point and have 100% confidence that everything is good", something like document storage might not be the best fit, because say a book genre might have changed, and a book that should be updated to "romcom" is still being called "romance". However, if quick means, I need to be able to snap my fingers and get an answer immediately, a relational database might not be all that helpful for you because you might have to wait at the end of a really long queue so that the database can tell you that it's very certain about your answer.
DALL-E: A simple sketch of a person in profile view looks off into the distance to see a stack of cubes like 3d excel spreadsheets 
There are no free lunches, only tradeoffs you can make and come to terms with as a developer.