Hooking Up AWS Appsync to S3 in 6 Hours(ish)
Or, how I finally sold my soul to Jeff Bezos I mean Andy Jassy I mean AWS.
I was having a discussion with some teammates the other day and they were talking about using an older monolith to stick some lookup data for retrieval across services. And I, the swaggering hot shot staff engineer, asked “why don’t you put that in a lambda?”
There was a lively back and forth but a couple of things fell out for me:
- I finally understood the power of having compute available outside of service boundaries
- Holy sh** Id never actually implemented the thing I was recommending (like the good thought leader I am)
It was also at this point that I realized it might be possible to not even set this up with a lambda, and instead direct connect from Appsync to S3. Some quickly googling showed me that someone had also done this https://gist.github.com/wulfmann/82649af0d9fa7a0049ff8dd1440291e4, so I wanted to dive in and try it for myself.
Overview
My basic thought was to create a simple Graphql Functionality that would accept an id and return a string with a generic name . The goal is to create the base layer of functionality, not to build a functioning system.
type Query {
name(id: ID!): String!
}// storage.json
{
"record": [
{
"id": "d9c9e7f6-8d3d-4a5d-9d3c-1b7e3c8a8c1a",
"name": "Tess"
}
]
}I knew that it was possible to treat S3 like a simple storage mechanism, and I'd heard that you could even do some pretty fancy stuff when it came to more complex queries from within a JSON or CSV file that's stored in S3. So I wanted to test it out for myself to see what it would look like. I'm going to walk you through how I set it up and what I learned.
If you want to skip ahead to the results you can find them here: https://github.com/Stuwert/s3-appsync-storage.
Steps I Took
- Setting up a manually versioned s3 bucket
- Experimenting with the query functionality directly
- Creating a graphql api
- Connecting the data source and debugging
- Testing out a different pattern
- Depreciating the bucket for one managed within the same template
1. Setting Up Manual S3 Bucket with Versioning
I wanted the JSON itself to be rather straightforward. A single file with an array of objects that stored values with an id for retrieval. I'd heard about S3 Select to query for data, so I started by manually creating a bucket in S3 and then uploading my storage file. The versioning component here might not have been that important, but I wanted to understand exactly how s3 versioned a file being uploaded repeatedly.

As you can see, I chose a very formal name.
I uploaded the storage.json file a couple of times, and noticed that the versions helpfully showed up in a tab in the UI.
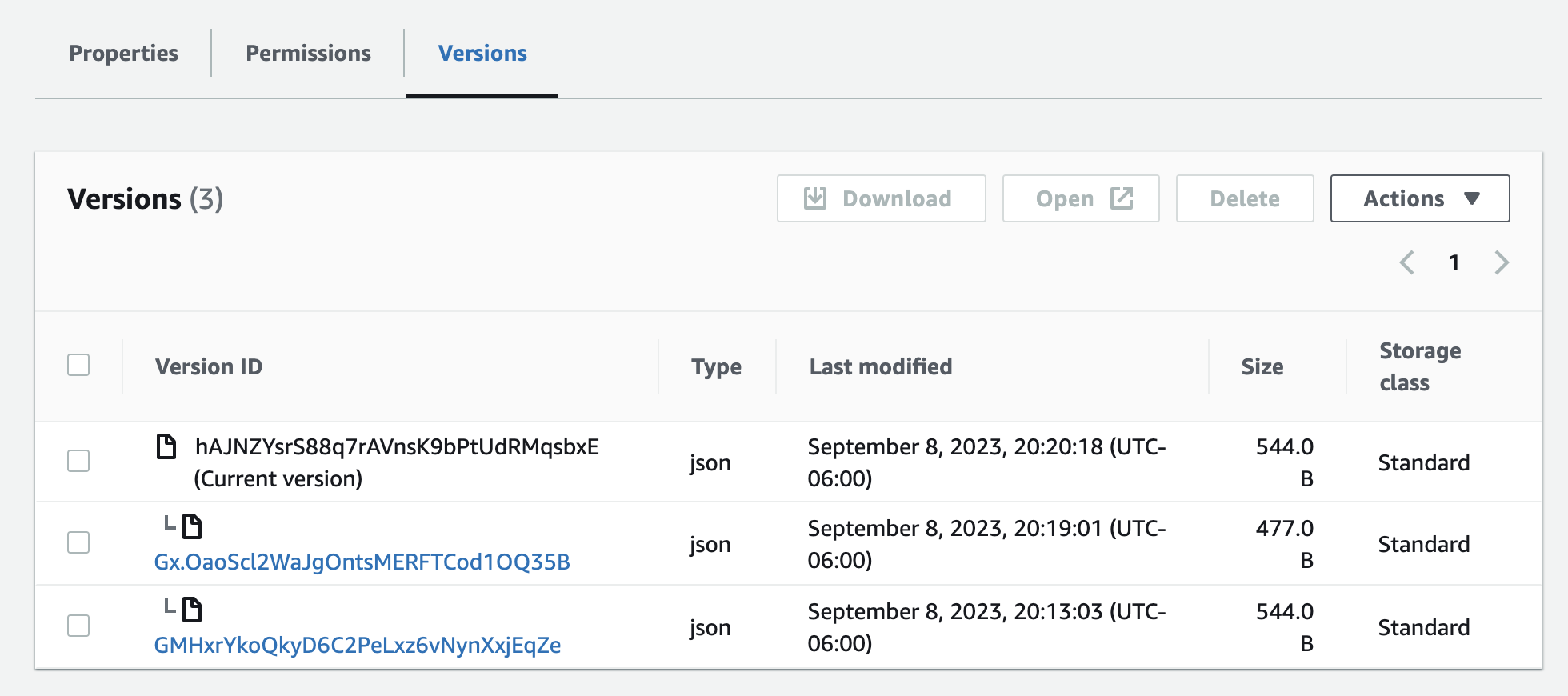
I know it's also possible to actually access these versions (though probably not so important). What I liked most about it is that it makes it incredibly easy to see what versions would be live at what time, which would make debugging significantly easier in the future.
2. Experimenting with the Query Functionality
Within the Actions button there's an option to test out querying:
This would come in handy for a couple of different reasons. Firstly to help me understand how to write a valid query, and secondly to help me reference and build the query within my HTTP Resolver when the time came.
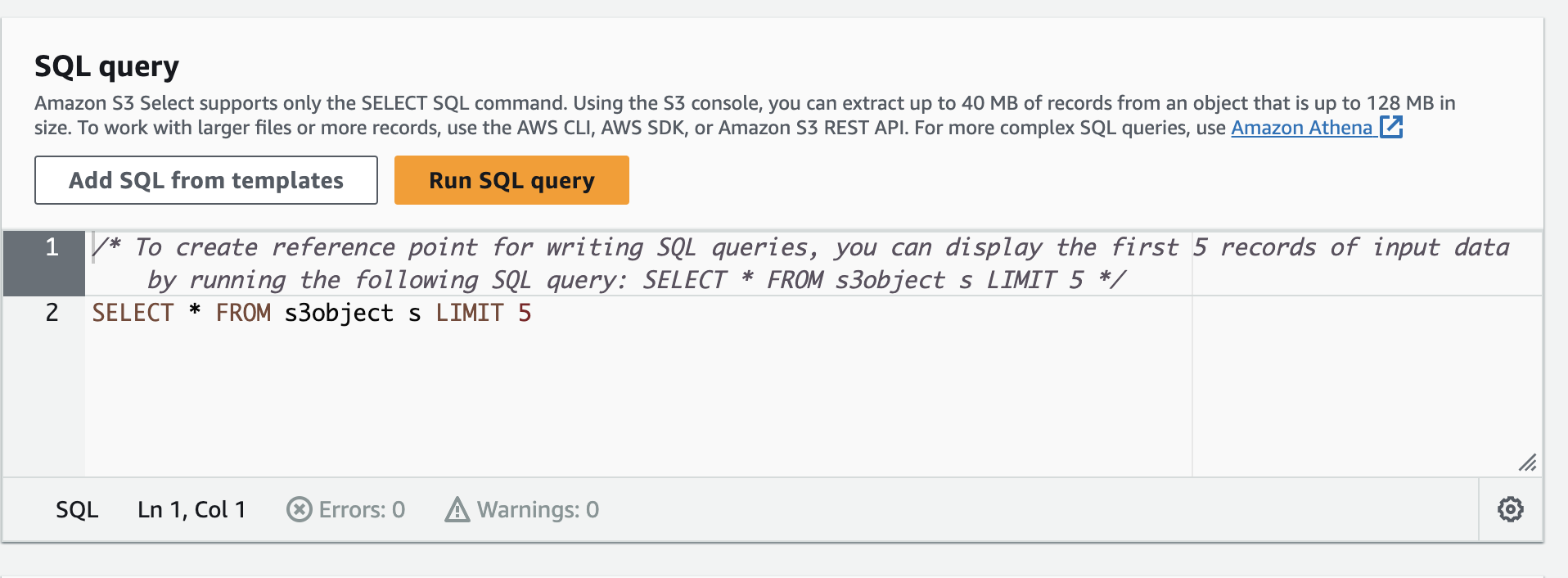
The bulk of the action lived within this console, with me testing out how exactly to write a query that gave me the results I wanted. The biggest challenge to start was trying to figure out how to get it simply to return a row of arrays from the JSON object I stored. At first I even tried changing the pattern of the JSON object to only being an array without the parent reference.
// storage.json
[
{
"id": "d9c9e7f6-8d3d-4a5d-9d3c-1b7e3c8a8c1a",
"name": "Tess"
}
]But that just resulted in S3 assigning it a single parent value like s1_ for reference, so I knew this wasn't the path I wanted.
SELECT command - Amazon Simple Storage Service
It clicked once I found the right documentation and realized that the "Table" I wanted to reference was actually a sub-group of the object i.e. s3object[*].records . Previously I had tried SELECT * FROM s3object.records and that gave me errors. The way I've visualized this is that from an abstract perspective it's possible that there you could be multiple parent objects within the file with a records property, so the [*] is necessary to specify that we're looking within those objects.
Ultimately I landed on the following query
SELECT s.name FROM s3object[*].records[*] s WHERE s.id = [uuid];Each [*] component indicates that we're looking in every record contained within an array.
The output it gave me was
{
"name": "Tess"
}What was interesting here is this keyed me in to the fact that the JSON response would give me an object that I would have to parse.
Within the request there were options for input and output formatting. Input formatting had to map to the file being parsed. So given that I stored a JSON file I had to parse it with JSON properties. However, the output formatting was independent, so I could choose to specify either JSON or CSV for the result. If I went with CSV I noticed I would actually just be given the single name instead of an object. I decided to stick with JSON as it seemed easier to parse in code later.
3. Creating the Graphql API
I went with AWS SAM to create the graphql template, though I heavily referenced the work for this CDK Gist to help set up the logic: https://gist.github.com/wulfmann/82649af0d9fa7a0049ff8dd1440291e4
There are a couple of components I want to highlight here:
GraphQLAPIKey:
Type: AWS::AppSync::ApiKey
Properties:
ApiId: !GetAtt GraphQLAPI.ApiIdSetting up the API Key for the Appsync service was surprisingly easy, just a couple of lines of config.
BucketDataSource:
Type: AWS::AppSync::DataSource
Properties:
Type: HTTP
ApiId: !GetAtt GraphQLAPI.ApiId
BucketQueryResolver:
Type: AWS::AppSync::Resolver
Properties:
Kind: UNIT
Runtime:
Name: APPSYNC_JS
RuntimeVersion: 1.0.0
ApiId: !GetAtt GraphQLAPI.ApiId
DataSourceName: !GetAtt BucketDataSource.Name
FieldName: characterName
TypeName: Query
CodeS3Location: getNameComplex.jsEspecially now that JS resolvers are available everywhere, getting these components set up was incredibly straightforward, just a couple of lines of config and the connections were functioning.
4. Connecting the DataSource and Debugging
The biggest challenges that I ran into were trying to format the request appropriately and then authorizing my HTTP Datasource so that it could make the request. For a variety of (probably reasonable) reasons, AWS doesn't give you a ton of details when you're running these errors, so here's what I learned.
Firstly, if you're hooking up a data source that's invoking another AWS Service, make sure you have your ServiceRoleArn, and Authorization Config set up together
ServiceRoleArn: !GetAtt ServiceRole.Arn
HttpConfig:
AuthorizationConfig:
AuthorizationType: AWS_IAM
AwsIamConfig:
SigningRegion: us-east-1
SigningServiceName: s3My Cloudformation wouldn't deploy at one point and I was getting the following error The validated string is empty because I had AuthorizationConfig set within the HTTPConfig but hadn't assigned it a Service Role. The validation error is not helpful, so it's important to get these wired up at once.
The SigningRegion represents the region where you're deploying the service and the SigningServiceName represents the service you're calling out to. If that's an AWS Service you'll use the AWS Service Name, but if you're say, invoking an API Gateway, you'll actually use the name of the gateway instance, not the AWS Name of the service it's built on.
Secondly, getting permissioning and request parameters correct was a challenge. I received a variety of Runtime Error and then 403 and 405 from S3 because I didn't have permissions set up correctly or because I wasn't sending the right request. To handle an S3 Select query, it's an XML Post request.
Copy-pasta-ing from the Network tab within the S3 Bucket playground came in a ton of handy here. Their documentation is actually pretty solid, but finding something to reference was very useful. https://docs.aws.amazon.com/AmazonS3/latest/API/API_SelectObjectContent.html
Finally, dealing with the response wasn't as straightforward as I had hoped. It actually returns a buffered string which you have to process on your own. Because the APPSYNC_JS execution environment doesn't have buffer tools (yet) https://docs.aws.amazon.com/appsync/latest/devguide/built-in-util-js.html, I went with a hackier approach and just split the string on values I determined would always be present.
You can find a reference to the full resolver here: https://github.com/Stuwert/s3-appsync-storage/blob/main/getNameComplex.js
5. Trying a Simpler Approach
Once I had the complex approach done, I wanted to see what loading the file in the resolver and then looping to grab the value would look like. https://github.com/Stuwert/s3-appsync-storage/blob/main/getNameSimple.js Frankly, it was a lot more straightforward, and didn't require hacks to manage. If it were guaranteed that the size of the json file were to stay fairly small (or be split up into multiple json files), this is probably the approach I would recommend. I sure felt smart getting the S3 query working, but given how hacky dealing with the response was, I don't think it's worth managing.
The other benefit to the simple approach is that rather than an XML POST, it's a simple GET request that parses and loops over the JSON.
6. Deprecating the Manual Bucket for a Programmatic One
From there, my final step was to get rid of the manual bucket and put one in the same template as the Appsync API.
StorageBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: name-storage-bucket
VersioningConfiguration:
Status: EnabledIt was very straightforward to do, and I could replace a bunch of string ARNs with variable references Resource: !GetAtt StorageBucket.Arn which had the benefit of making me feel like a #realengineer.
I want to call this out because I think it's easy when testing new code to go from 0 to 1000 and try to automate all of the things. It's always best to start by doing nothing. I found the combination of manual and automatic integration helpful to reduce the number of moving parts, and inject some certainty into what I was doing. Then, when I was ready to fully automate, it was a simple change.
7. Next Steps
I didn't do the final step of fully wiring this in with something like a Github action to upload the files to s3 on code change. https://github.com/marketplace/actions/upload-s3 I also didn't add authorization (which you can also implement within your Graphql Unit Resolvers).
That would take this from a toy to a functioning service, but I didn't think it was necessary to take those steps because the core of the challenge was reading stuff from S3 without a lambda.
What Did I Learn?
Live look at me building a bridge of knowledge
 Paris Bridge by Arthur B. Carles, American, b. Philadelphia, Pennsylvania, 1882–1952
Paris Bridge by Arthur B. Carles, American, b. Philadelphia, Pennsylvania, 1882–1952
My recommendation got me thinking about how in the last 10 years if you needed a computer to do a thing for you (however small) you needed to find some sort of server abstraction to stick it onto, and hope that it fit well enough that you could maintain it. But with the power of AWS compute is now a “freely available” resource that you can pluck out of thin air. What this means is that, instead of thinking about problems in terms of what gravitational orbit they might fall closest to, we can think about them in terms of what is easiest for us to support and maintain, and ultimately deprecate.
But this work actually pushed me even further to realize that the real benefits of "serverless" aren't actually the ability to push lambdas up to the cloud that live outside of big monoliths. I totally understand why, if your choices are between trying to spin up a new lambda to "do a thing" or to "add some code to a monolith" you'd go with the latter. The costs to doing the code and getting the lambda happy and dealing with cold starts are real. But... if you can decouple compute (heavy lifting that your backend does) from data access (serving stuff that your frontend needs), you can ship small and simple units of change that don't require a lot of maintenance. For example, if I wanted to move this to Dynamo in the future, it would be (I don't want to say trivial because there lies danger) a relatively simple pattern to update my datasource and swap out the resolvers doing the work, without changing the interface, or needing to manage too much of the underlying code.
The other thing I realized is that half of the reticence with my earlier recommendation is the fact that you have to stitch a lambda between Appsync (your graphql provider) and S3, your storage. Spinning up a lambda means doing stuff like managing Node or Python versions, packages, and references. Doing a direct connect is closer to 4-5 files that you could reasonably put in any repo that you feel fits.
I don't like the phrase "the best code is no code", but I've really been leaning into this idea that good code should be easy to replace and remove, and what I love most about this implementation is how small the surface area is to get rid of. If I wanted to deprecate this in the future it would be a process of removing the cloudformation stack, and archiving a repo (or deleting the files), it's a much smaller imprint than trying to pull out old code!
Hope this helps!